Feature-preprocessing/engineering leakage during data-preparation and Train-Test Split Strategy Protocol [Stacking, meta-model]
Are we allowed to transform the input data in any way we want? Can we train sub-models to preprocess features? Can we use a pipeline of models? Can we use the output of one model as an input of another model?
Assume we have a supervised learning problem (== we have a label), and we would like to preprocess a feature using a separate supervised model, so that we have two models in a chain, both are trained on the same label.
Problem 1: Different train/test split (=test set leakage), 100% test accuracy for model A (target leakage).
We would like to predict a 0-1 label (boolean), using 2 features: 1 numerical and 1 textual feature, using a decision tree (call it model A). Since decision trees use numbers, we would like to take the textual feature and transform it using a separate supervised model that takes a textual input, predicts a scalar label (call it model B), and use this model to convert the textual feature into a numerical feature, so that we will have 2 numerical features, and then use a decision tree to predict the 0-1 label (boolean).
The question is whether this process is legitimate. And if it is legitimate, are there any restrictions on the process to make it legit?
To make it more specific, can we first train model B, any way we want, and then transform the feature and train model A? Can we do a train/test split anyway we want (randomly) during training model B, and then do a train/test split (randomly) during training model A? Or must the split be the same during the training of model B and model A? If this requirement is needed, it can be a bit complicated in real life scenarios, where you need to enforce the same train/test split procedure in all ML teams in an organization involved in the project.
Let’s make the problem even simpler: Assume that the textual feature is just a random string, meaning that it carries zero information in it, and that the numerical feature is also random and has no correlation with the label. Assume we have 1000 examples.
So, we train model B in a very overfitted manner, meaning that the training accuracy (800 examples) is 100%, and test accuracy (200 examples) is 50% (random guessing). This can happen when the model memorizes all the random texts that correspond with 0-labels and all the texts that correspond with 1-labels. That means that transforming the textual feature using model B will convert the training set features into the training-labels themselves.
Now, let’s say that in model A training, 100% of the examples in the test-set (200 of 200) are actually train-set examples of model B (because we did a new random train/test split). As for the training-set, 600 out of the 800 are examples that were part of the training-set of model B. They are completely overfitted, so they (the features) contain the label itself. The other 200 are random and have no correlation to the label. So training A will yield a model that simply uses the overfitted feature, generated by model B, to predict the label. Therefore, the test accuracy of model A will be 100%, although the features have zero information in them, because the transformed feature predicts exactly the label.
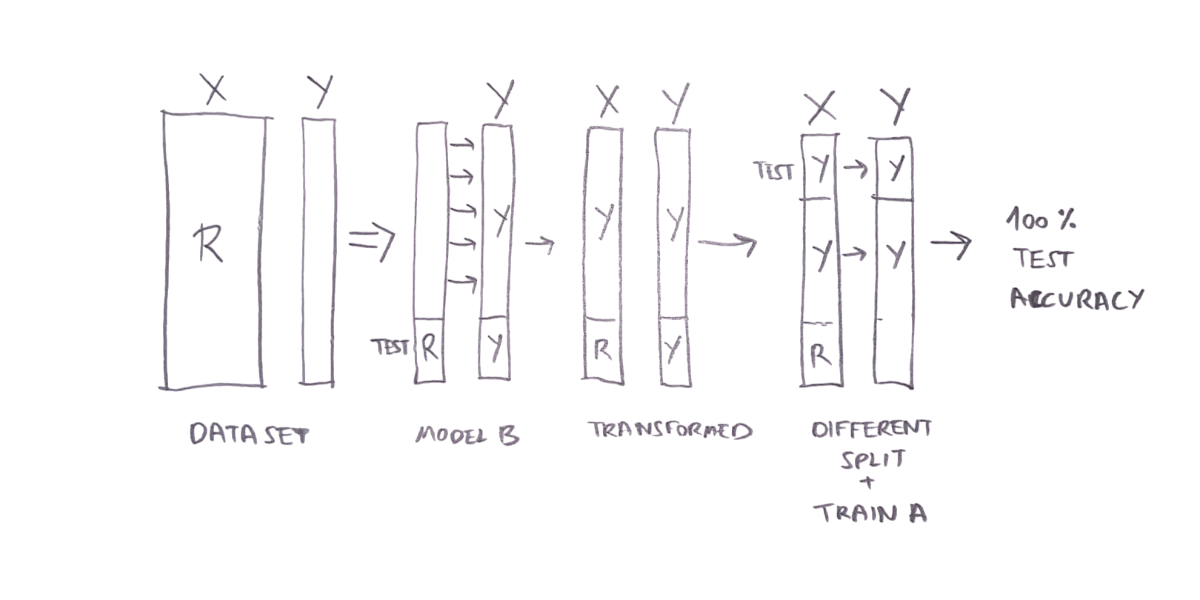
This is an example of a case where features are completely random, but we reached 100% test accuracy. We could have tweaked the example to reach any test performance we wanted.
I call this “Preprocessing Leakage”. If we would have kept the train/test split identical across model B and model A, this specific problem would have been avoided. So the rule here:
never evaluate a model on a test set which contains features coming from a different model predictions was trained on.
Mitigation: One way to solve this preprocessing leakage is to avoid a random train/test split, but rather do the split deterministically, using a stable hash function over the examples. For example, split by the hash of the user id, account id, etc., so that all sub-models will have the same train/test split. This also means having full control over the train/test split, and avoiding using different third-party libraries that each can split the data in a different way.
Another way, if it’s possible, is to do the split before the training of any model. This is not always possible in an organization which has a feature store where many teams insert new features to the databases, and sometimes insert trained-features into the databases. Having full control on the way every team trains the feature-models can be very difficult. In many cases, there are many features you don’t even know the meaning of, let alone the way they were injected, using some trainable model you’re not responsible for.
The train/test split is important, and we need to keep it under control.
Problem 2: in-fold predictions, 100% train accuracy for model A (optimistic bias)
However, that’s not the only problem. Even if we keep the last model (aka meta-model) with a completely private held-out test set, we still have another issue. We trained the base model (model B in our diagram) and then we predicted the value (feature for the second model) for each example, both in train and test (of first model) and fed it into the second (meta) model for training. If model B overfitted the data completely, the meta model (model A) sees training data that a large part of it is already identical to the label (e.g. 80%), so model A will be over optimistic, thinking that it did a very good job (high training accuracy), while it will not generalize well to its held-out test set (low test accuracy). The rule here is that the features generated by the first model must come from model A which was trained on anything but what it predicts. This is called out-of-fold (OOF) prediction. The standard way is to split the data of model B into K parts, for example 5 parts, and then for five times train on 4/5 of data, and predict the remaining 1/5 of data. Only those predictions are fed into the second, meta model. So the rule here:
Rule 2: A model should never send out the predictions it made on examples which it was trained on.
But we can see that rule 2 is stronger than rule 1: If a model never sends out predictions on examples it had trained on, the first problem (of 100% test accuracy) can never happen.
Implications
If we have only a single (stand-alone) model we can train it once, but when we have a chain of two or more models, we need to train each model which is not the final meta model a few times (K), typically 5 times.
By the way, after the second model was trained, it is perfectly fine to re-train (re-fit) the first model on the full training set, given that the held-out set is external to the training set of both models. So the best practice is to have the same train/test split for all models in the chain, models never train on test, and models never forward predictions to a successive model which they trained on.
Appendix
Train-Test Split Strategy Protocol
Seed-Stable: Sometimes, when the dataset is not too large, you don’t want a three-way split: train/dev/test, in order to avoid losing data for the training set. However, when you split into only train+test, you risk overfitting the test_set. So, after you fixed the test_set and measured the metrics, you can take the all_set, split it differently using a different random seed to a different train/test split, train the model again and evaluate on the new test_set. If the two evaluations, each using a different random seed, are pretty much the same, we call it seed-stable. You can do more re-trainings, using different seed-splits, to increase the confidence in the seed-stability, and then it is quite similar to k-fold Cross Validation or Monte Carlo Cross-Validation. In any case, when a few ml-teams are using a shared dataset to develop models for sub-tasks or pipeline of models in which a model output is used as an input to another model, all published models must not use any examples from the shared global test_set for their final training which is used to publish the model.
Access Safety: On the one hand, we don’t want training loops to accidentally have access to a folder or a database containing both the train+test examples, to avoid mistakes that a model trains on a test example. On the other hand, often examples do reside in one folder/database, and all_set keeps growing when we have more examples. So, a solution is to hold a file called split.json which will hold the split, and all the training procedures (in various ML teams) will have access to this file, which will point to the examples/files in the database/directories.
Who is generating the split.json file? It is generated by a program which receives a folder or a database of unsplit examples, and creates the split_file. If the file does not exist, it randomly splits the examples in the folder and saves the file. If the file does exist, it runs: (a) validation procedure, to make sure the file is valid: no overlapping, no less pointer, no more pointers, etc., and (b) update procedure. Every sub-algorithm, sub-model or derived dataset must use the global split file in order to make the train dataset and the test dataset, and run the validation procedure.
Each ml-team can check that the model is seed-stable on a different seed-split of the all_set, to make sure the model does not overfit the test_set, or alternatively use a different seed-split as develop_set, but their published model must use the global split as defined by the split_file.
Observation: in some companies, where you have different ml-teams working on different models which use the same data and may interact with each other, they must agree on a shared split_file, or alternatively have an external coordinator that specifies this split_file for them. The interaction of models can be in the form of a sequential-chain, that is the output of a model is the input of another model, or models that work in parallel, each working on a sub-task. Example: An image taken from an autonomous car, where one model segments the objects which are cars, and another model classifies the car into models.
How to make sure the ml-teams do not ‘cheat’? A team can cheat and overfit to the test_set. It is difficult for the organization to detect it. The only way to overcome this is to completely hide the global test_set from the teams. However, this means the teams will have less data to work with.
Save split inside model: When we are given a published model file (architecture+weights), how can we tell what images are we allowed to evaluate it on, in case it comes from a different ml-team? When saving a model to disk, save the set of filenames/pointers of examples used for training or the set of hashes of examples/features used for training, as part of the model state: model.split_context (register_buffer). When loading a model from disk, make sure the test_set you plan to validate the model on, and the model.split_context do not overlap. This way, you can be more sure that the evaluation you are doing is solid and correct. Optionally, if the model.split_context is less than the current global split training set, you can print a warning message that the model could be retrained with more training data.
What happens when the pre-split dataset grows (the all_set)? We want the existing models to remain valid. That means, an old example must stick to its previous train/test affiliation. A train example cannot move to be a test example, otherwise the model will overperform. A test example can become a training example theoretically, but I don’t see a necessity for this to happen. That means, when we re-split, we cannot do it with a random-seed split, but rather preserve the previous split affiliation, and for each new example, in some predefined probability, assign it to either train or test. When the dataset grows, we have the flexibility to change this probability, if for example we want to increase the ratio of the training set size to test size.
Dataset Derivatives: Sometimes, an ml-team needs to make derivatives of the dataset. For example: The dataset contains images of a front camera of a car. Model A does instance segmentation of cars with 2 classes (background/foreground), and model B uses the 512x512 bounding box to classify the cars with 100 classes. Team B would like to create a dataset of cars, and this dataset is extracted from the root dataset, which makes it a derivative. Now, Model B stands by itself: It can be evaluated standalone, regardless of model A. However, it can also be evaluated and used in tandem, as part of the full pipeline, which is finding cars in the image (model A) and classifying them (model B). So, in the two scenarios you want all the safety measures to be in place. It means that the split_file should include a pointer to the parent split_file, and the model.saved_training_set should also include the set of training images used in the parent split_file. This will allow you to safely evaluate the model both on the parent dataset and the derivative dataset.
Model evaluation principles: Sometimes, when you use data augmentation for training, you may decide to use augmentations for the test_set as well. For example, if your test_set is not big enough and you want to enlarge it. Or, if you want to make sure the model’s generalization can withstand the transformation. In those cases, where the evaluation process involves randomness, you need to make sure you set the RNG seed before the evaluation, for the evaluation to be consistent during different RNG states, either on the same computer or across computers. However, this may drastically ruin the training process, as when you return from the evaluation procedure, the next training batch starts from the same RNG state. Therefore, before setting the evaluation seed, you must save the RNG state, and restore it at the end:
# Save the current RNG states, before doing the evaluation, after a few training cycles
rng_state_torch = torch.get_rng_state()
rng_state_cuda = torch.cuda.get_rng_state_all() if torch.cuda.is_available() else None
rng_state_random = random.getstate()
rng_state_numpy = np.random.get_state()
seed_everything(dice_classifier_train_seed)
model.eval()
eval_loss = 0.0
full_labels, full_outputs = [], []
with torch.no_grad():
for images, labels in test_loader:
# …
# Restore the original RNG states, to allow the training randomness needed
torch.set_rng_state(rng_state_torch)
if torch.cuda.is_available():
torch.cuda.set_rng_state_all(rng_state_cuda)
random.setstate(rng_state_random)
np.random.set_state(rng_state_numpy)
If you want to be more sure about your evaluation results:
(1) Do a sanity check, and sometimes run the evaluation procedure twice, and make sure you get the exact same results. This helps to validate that the RNG seeds were properly set and that nothing was forgotten.
(2) Make sure that the evaluation which happens every few steps during training is identical to the evaluation results after fresh loading of the model from the disk. Meaning the last evaluation loop in training, which happens before the model was saved to disk, should be identical to the evaluation of a loaded model, without training at all.
To help maintain consistency in evaluation, you want to make sure the data-loader has persistent_workers=False, so that every evaluation cycle will start from the exact same RNG state, with no leftovers from the previous evaluation cycle:
def worker_init_fn(worker_id):
seed = 42 + worker_id
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
data_loader_test = DataLoader(dataset_test, batch_size=batch_size, shuffle=False,
num_workers=num_workers,
persistent_workers=False, # persistent_workers must be False for consistent results!!
collate_fn=lambda x: tuple(zip(*x)), worker_init_fn=worker_init_fn, generator=torch.Generator().manual_seed(seed))
Rarely, the evaluation procedure contains a .train() part. This can happen when you use some model libraries that return certain metrics and results (like loss) only when in .train() mode. If this is the case, and the model uses BatchNorm, you must save and restore BatchNorm state, before and after the .train() part, otherwise the .train() part in your evaluation procedure will have side effects on the training process of the model:
def save_batchnorm_state(model):
bn_states = []
for module in model.modules():
if isinstance(module, (nn.BatchNorm2d, nn.BatchNorm1d)):
bn_states.append({
"running_mean": module.running_mean.clone(),
"running_var": module.running_var.clone(),
"num_batches_tracked": module.num_batches_tracked.clone() if hasattr(module, "num_batches_tracked") else None
})
return bn_states
# Function to restore BatchNorm states
def restore_batchnorm_state(model, bn_states):
i = 0
for module in model.modules():
if isinstance(module, (nn.BatchNorm2d, nn.BatchNorm1d)):
module.running_mean.copy_(bn_states[i]["running_mean"])
module.running_var.copy_(bn_states[i]["running_var"])
if bn_states[i]["num_batches_tracked"] is not None:
module.num_batches_tracked.copy_(bn_states[i]["num_batches_tracked"])
i += 1
The full code
Here is a class I created, DatasetSplitter, that implements the concepts specified above:
import os, torch, json, hashlib, random
from pathlib import Path
class DatasetSplitter:
@staticmethod
def _calculate_file_hash(file_path):
"""Calculates a 6-character alphanumeric hash for a given file."""
hasher = hashlib.md5()
with open(file_path, 'rb') as f:
buf = f.read()
hasher.update(buf)
return hasher.hexdigest()[:6]
@staticmethod
def validation(all_files, split_file_path):
"""
Validate that split_file_path file do not have same entry for train and test
Validate that all_files matches the files in the split file.
"""
with open(split_file_path, 'r') as file: split_data_loaded = json.load(file)
train_set, test_set = split_data_loaded['train'], split_data_loaded['test']
all_files_in_split = {entry['path'] for entry in train_set + test_set}
def find_duplicates(input_list, error_message):
seen, duplicates = set(), set()
for item in input_list:
if item in seen: duplicates.add(item) # Add to duplicates if already seen
else: seen.add(item) # Mark as seen
if duplicates:
raise ValueError(f"{error_message}: {', '.join(map(str, duplicates))}")
# validations
find_duplicates([entry['path'] for entry in train_set], "Train set contains identical path")
find_duplicates([entry['hash'] for entry in train_set], "Train set contains identical hash")
find_duplicates([entry['path'] for entry in test_set], "Test set contains identical path")
find_duplicates([entry['hash'] for entry in test_set], "Test set contains identical hash")
find_duplicates([entry['path'] for entry in train_set]+[entry['path'] for entry in test_set], "Train and test sets overlap in filename path")
find_duplicates([entry['hash'] for entry in train_set] + [entry['hash'] for entry in test_set], "Train and test sets overlap in hash")
# Ensure all files exist and have matching hashes
for entry in train_set + test_set:
file_path, file_hash = entry['path'], entry['hash']
if not os.path.exists(file_path):
raise ValueError(f"File {file_path} listed in split file does not exist!")
actual_hash = DatasetSplitter._calculate_file_hash(file_path)
if actual_hash != file_hash:
raise ValueError(f"Hash mismatch for file {file_path}: expected {file_hash}, got {actual_hash}")
# Ensure no extra files in dataset folder
actual_files_in_folder = set(all_files)
if extra_files := actual_files_in_folder - all_files_in_split - set([split_file_path]):
print(f"DataSplitter.validation Warning: The following files are in the folder but not in the split file: {extra_files}")
@staticmethod
def folder_to_list_of_files(dataset_folder):
return [
str(file.resolve())
for file in Path(dataset_folder).glob('**/*')
if file.is_file() and not file.name.endswith('.json')
]
@staticmethod
def update(list_of_files, split_file_path, train_size):
with open(split_file_path, 'r') as file: split_data = json.load(file)
train_set = split_data['train']
test_set = split_data['test']
set_train_hash = set([entry['hash'] for entry in train_set])
set_train_path = set([entry['path'] for entry in train_set])
set_test_hash = set([entry['hash'] for entry in test_set])
set_test_path = set([entry['path'] for entry in test_set])
all_files_in_split = {entry['path'] for entry in train_set + test_set}
# Add new files to train or test sets
actual_files_in_folder = set(list_of_files)
new_files = actual_files_in_folder - all_files_in_split - set([split_file_path])
print(f"Found {len(new_files)} files in the folder which are not in the train set or the test set.")
for file_path in new_files:
file_hash = DatasetSplitter._calculate_file_hash(file_path)
# first, make sure the path and hash of file is not in train_set or train_set
if file_path in set_train_path:
print(f"WARNING, new file {file_path} in already in train_set, skipping.")
continue
if file_path in set_test_path:
print(f"WARNING, new file {file_path} in already in test_set, skipping.")
continue
if file_hash in set_train_hash:
print(f"WARNING, hash {file_hash} of new file {file_path} in already in train_set, skipping.")
continue
if file_hash in set_test_hash:
print(f"WARNING, hash {file_hash} of new file {file_path} in already in test_set, skipping.")
continue
if random.random() < train_size:
train_set.append({"path": file_path, "hash": file_hash})
set_train_path.add(file_path)
set_train_hash.add(file_hash)
print(f"Added {file_path} to train set.")
else:
test_set.append({"path": file_path, "hash": file_hash})
set_test_path.add(file_path)
set_test_hash.add(file_hash)
print(f"Added {file_path} to test set.")
split_data['train'] = train_set
split_data['test'] = test_set
with open(split_file_path, 'w') as file: json.dump(split_data, file, indent=4)
@staticmethod
def create_or_update_root_split_file(all_files, split_file_path, train_size):
"""
If split_file_path does not exist, takes the dataset_folder, scan all the files in it, shuffle the list, and split the files into
train and test sets, according to the train_size portion. Then, it creates the split_file_path json file, and save in it the two sets:
the train set and the test set. All the file names in the split file should have absolute path.
If the split_file_path already exists, it starts by running a separate validation() function: Read the file, check that the train set and the test
does not overlap. If they do, it raises an exception. It also makes sure all the files in the train and test sets are in the dataset_folder.
If they are not, it raises an exception. It also checks that there are no additional files in the folder that are not in the split file.
If there are, output a warning message that the split file is can be updated.
Then, it runs the update() function: For any NEW file in the folder, that is not in the split file already (either in train or test), it randomly
assign it to train set with probability of train_size, and to test set with probability of 1 - train_size and prints a message explaining was
is the new file affiliation. Then it saves the updated split file.
In general, for any file in the split_file, besides the full path of the file, also include a 6 alphanumeric hash of the file content, so that
if the filename is changed in the future, it's signature will be preserved. In the validation() function, also make sure each hash in the split_file,
matches the true hash of the file in the folder.
split_file should include additinal field: "parent" that is the path to the parent split file, if it exists. If it does not exist, it should be null.
"""
if os.path.exists(split_file_path):
# Validate and update existing split file
DatasetSplitter.validation(all_files, split_file_path)
DatasetSplitter.update(all_files, split_file_path, train_size)
else:
random.shuffle(all_files)
split_point = int(len(all_files) * train_size)
train_files = all_files[:split_point]
test_files = all_files[split_point:]
split_data = {
"parent": None,
"train": [{"path": file, "hash": DatasetSplitter._calculate_file_hash(file)} for file in train_files],
"test": [{"path": file, "hash": DatasetSplitter._calculate_file_hash(file)} for file in test_files],
}
with open(split_file_path, 'w') as file:
json.dump(split_data, file, indent=4)
print(f"Created new split file at {split_file_path}.")
@staticmethod
def create_split_file_from_splitted_lists(list_files_train, list_files_test, split_file_path, parent_split_file):
"""
If the file split_file_path does not exist, it will create it using the two lists. It will make sure the lists do not overlap.
If the parent_split_file is not None, run the validation() function on the parent, and all ancestors.
"""
# Ensure no overlap between train and test sets
train_set, test_set = set(list_files_train), set(list_files_test)
if train_set & test_set: raise ValueError("Train and test sets overlap!")
# Validate the parent split file if provided
if parent_split_file:
current_parent = parent_split_file
while current_parent:
if not os.path.exists(current_parent): raise ValueError(f"Parent split file not found: {current_parent}")
DatasetSplitter.validation(all_files=DatasetSplitter.folder_to_list_of_files(os.path.dirname(current_parent)),
split_file_path=current_parent)
with open(current_parent, 'r') as parent_file: parent_data = json.load(parent_file)
current_parent = parent_data.get("parent")
split_data = { # Create the split file content
"parent": parent_split_file,
"train": [{"path": file, "hash": DatasetSplitter._calculate_file_hash(file)} for file in list_files_train],
"test": [{"path": file, "hash": DatasetSplitter._calculate_file_hash(file)} for file in list_files_test],
}
# Save the split file
with open(split_file_path, 'w') as file: json.dump(split_data, file, indent=4)
print(f"Split file created at {split_file_path}.")
@staticmethod
def add_split_context_to_model_before_save(split_filepath, model):
"""
This will add a field/buffer to a model (not a Parameter), called split_context, which is a list. The first element in the list
is the content of the json object in the split file. If the split_file has a parent, including the parent content as the second element, and
so on. This field will allow users of the model to make sure they do not evaluate the model on an example which is included in the training set,
of the split_file or its ancestors.
This is an example of how you should use it:
DatasetSplitter.add_split_context_to_model_before_save(split_filepath, model)
torch.save(model.state_dict(), model_save_path)
"""
split_context = []
# Traverse the split file hierarchy
current_split_filepath = split_filepath
while current_split_filepath:
# Load the current split file
if not os.path.exists(current_split_filepath):
raise ValueError(f"Split file not found: {current_split_filepath}")
with open(current_split_filepath, 'r') as file: split_data = json.load(file)
split_context.append(split_data)
# Move to the parent split file, if it exists
current_split_filepath = split_data.get("parent")
# Serialize split_context as JSON and register as a tensor buffer
serialized_context = json.dumps(split_context)
context_tensor = torch.tensor(list(serialized_context.encode()), dtype=torch.uint8)
model.register_buffer("split_context", context_tensor)
@staticmethod
def get_list_of_train_files_and_test_files(split_filepath, compare_to_this_total_list):
"""
Load the split file, and return the list of train files and test files.
If compare_to_this_total_list is not None, it will validate that the union of test_files and train_files is equal to compare_to_this_total_list
"""
if not os.path.exists(split_filepath): raise ValueError(f"Split file not found: {split_filepath}")
with open(split_filepath, 'r') as file: split_data = json.load(file)
train_files = [entry['path'] for entry in split_data.get('train', [])]
test_files = [entry['path'] for entry in split_data.get('test', [])]
if compare_to_this_total_list is not None:
all_files = train_files + test_files
# Compare the two sets
if set(all_files) != set(compare_to_this_total_list):
missing_from_split = set(compare_to_this_total_list) - set(all_files) # Files in folder but not in split file
extra_in_split = set(all_files) - set(compare_to_this_total_list) # Files in split file but not in folder
raise Exception(
f"Split file [{split_filepath}] can be updated. Differences:\n"
f"Missing from split file: {missing_from_split}\n"
f"Extra in split file: {extra_in_split}"
)
return train_files, test_files
@staticmethod
def validate_model_after_load(split_filepath, loaded_model):
"""
Here we want to make sure that the test_set which is described in the split_filepath, or any of its ancestors (union) does not overlap
with any of the loaded_model.split_context content, both in respect to the filenames, and to the hashes.
This is an example of how you should load a model:
loaded_state_dict = torch.load(model_path, map_location=device, weights_only=True)
model.register_buffer("split_context", loaded_state_dict["split_context"])
model.load_state_dict(loaded_state_dict)
DatasetSplitter.validate_model_after_load(split_filepath, model)
"""
# Deserialize split_context from the model
if not hasattr(loaded_model, "split_context"): raise ValueError("Loaded model does not have a `split_context` attribute.")
# Deserialize the split_context tensor into a Python object
serialized_context = bytes(loaded_model.split_context.tolist()).decode() # Convert tensor to bytes, then decode
split_context = json.loads(serialized_context) # Deserialize JSON string back to a list of dictionaries
del loaded_model
# Load the split file and its ancestors into a unified test set
current_split_filepath = split_filepath
all_test_files, all_test_hashes = set(), set()
while current_split_filepath:
if not os.path.exists(current_split_filepath):
raise ValueError(f"Split file not found: {current_split_filepath}")
with open(current_split_filepath, 'r') as file: split_data = json.load(file)
for entry in split_data['test']:
all_test_files.add(Path(entry["path"]).name)
all_test_hashes.add(entry["hash"])
current_split_filepath = split_data.get("parent")
for context in split_context: # Check for overlap between the test set and the model's split_context
for entry in context["train"]: # Validate against the training set in the context
filename = Path(entry["path"]).name
file_hash = entry["hash"]
if filename in all_test_files: raise ValueError(f"Filename {filename} in test set overlaps with training set in model context.")
if file_hash in all_test_hashes:
raise ValueError(f"File hash {file_hash} in test set overlaps with training set in model context.")
# print("Validation passed: No overlap between test set and model's training split_context.")
@staticmethod
def helper_split_annotation_file_according_to_splitfile(split_filepath, loaded_annotation_json_file):
"""
the loaded_json_file contains a list of annotations object. In each annotation object there is a field, according to this example:
"data": {
"image": "\/data\/upload\/3\/ee88667f-13.jpg"
}
Use only the filename in the json file, and ignore it's path. Then, check if the filename is in the split file. If it is not, raise an
exception. Otherwise, check if it is in the train set or test set.
The method returns two objects, the loaded_json_file which is filtered for training files, and for test files (but the loaded_json_file keep the
same structure, just with filtered elements in the top list)
"""
with open(split_filepath, 'r') as file: split_data = json.load(file) # Load the split file
train_files = {Path(entry["path"]).name for entry in split_data['train']}
test_files = {Path(entry["path"]).name for entry in split_data['test']}
all_split_files = train_files | test_files
train_annotations, test_annotations = [], []
for annotation in loaded_annotation_json_file:
# Extract the filename from the annotation
annotated_image_path = annotation["data"]["image"]
annotated_image_filename = Path(annotated_image_path).name
# Check if the file is in the split file
if annotated_image_filename not in all_split_files:
raise ValueError(f"File {annotated_image_filename} in annotations is not listed in the split file.")
# Assign to train or test set
if annotated_image_filename in train_files:
train_annotations.append(annotation)
elif annotated_image_filename in test_files:
test_annotations.append(annotation)
else: raise Exception("This should never happen.")
return train_annotations, test_annotations
if __name__ == '__main__':
DatasetSplitter.create_or_update_root_split_file(
all_files=DatasetSplitter.folder_to_list_of_files('/image_storage/'),
split_file_path='split.json',
train_size=0.75
)